1. Introduction
So, you know what Bayes theorem is and have learned how to write a Markov chain Monte Carlo algorithm. Life feels good and you are ready to set out and start seeing how you can use Bayesian inference to solve problems and impress your friends with posteriors and corner plots. Right!?
Unfortunately, real world research problems are often much more complex than the straightforward examples we encounter in textbooks and statistics classes. While it is always good to start simple, making the leap to something more realistic can be quite daunting…
The Bayesian workflow course is here for you! The idea with this course is to connect from an introductory class to the actual application of these methods to your research.
We will learn about:
Going from a science question to a statistical model
Defining sensible priors for your problem
Diagnosing problems in models and computation
Verification of a statistical model through simulations
Experiment design
Model comparison
How the course works
The course is scheduled to cover one week of intensive lectures/tutorials from the 13th September 2021 as part of the ODSL Block Course Practical Inference for Researchers in the Physical Sciences. The course is also designed such that it is self-contained and can be followed independently at your own pace.
All course information is contained in notebooks, and information on how to get set up and running can be found on the course website. If you have questions regarding the course, please feel free to contact me at f.capel@tum.de.
Further reading
It is impossible to cover many interesting and important things in a such a short course, so I will often make references to further reading in the Bayesian Data Analysis textbook and Michael Betancourt’s tutorials and case studies.
Are you ready?
Assumed prerequisites for the course are a basic understanding of Bayesian probability theory and Markov chain Monte Carlo (MCMC) methods.
We will be using the Stan statistical programming language to demonstrate a Bayesian workflow. In particular, we will use Stan’s implementation of Hamiltonian Monte Carlo (HMC) through the cmdstanpy python interface.
To start with, we will make sure everything is working by simulating some data from a normal distribution and verifying that we can fit the parameters of this distribution using cmdstanpy.
[1]:
import numpy as np
from scipy import stats
from matplotlib import pyplot as plt
from cmdstanpy import CmdStanModel
import arviz as av
[2]:
# simulate some data from a normal distribution
N = 50
mu = 5
sigma = 3
x = stats.norm(loc=mu, scale=sigma).rvs(N)
# plot histogram
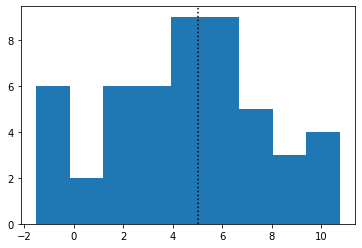
fig, ax = plt.subplots()
ax.hist(x, bins=np.linspace(min(x), max(x), 10))
ax.axvline(mu, color="k", linestyle=":")
[2]:
<matplotlib.lines.Line2D at 0x142f92a90>
To fit this data with Stan to try and recover mu and sigma, we need to write our model in the Stan language. More details can be found in the Stan user’s guide. The model for normal-distributed data looks like this:
data{
int N;
vector[N] x;
}
parameters {
real mu;
real<lower=0> sigma;
}
model {
x ~ normal(mu, sigma);
}
NB: by not specifying priors on the parameters
muandsigma, we implicitly define uniform priors over +/- infinity, or within the bounds given by<lower=L, upper=U>.
You can find this model in the file stan/normal.stan.
[3]:
# compile the Stan model
stan_model = CmdStanModel(stan_file="stan/normal.stan")
print(stan_model)
INFO:cmdstanpy:found newer exe file, not recompiling
INFO:cmdstanpy:compiled model file: /Users/fran/projects/BayesianWorkflow/src/notebooks/stan/normal
CmdStanModel: name=normal
stan_file=/Users/fran/projects/BayesianWorkflow/src/notebooks/stan/normal.stan
exe_file=/Users/fran/projects/BayesianWorkflow/src/notebooks/stan/normal
compiler_options=stanc_options=None, cpp_options=None
[4]:
# put data in dict to pass to the CmdStanModel
# the keys have to match the variable names in the Stan file data block
data = {}
data["N"] = N
data["x"] = x
# run HMC for 1000 iterations with 4 chains
fit = stan_model.sample(data=data, iter_sampling=1000, chains=4)
# check the results
fit.summary()
INFO:cmdstanpy:start chain 1
INFO:cmdstanpy:start chain 2
INFO:cmdstanpy:start chain 3
INFO:cmdstanpy:start chain 4
INFO:cmdstanpy:finish chain 2
INFO:cmdstanpy:finish chain 1
INFO:cmdstanpy:finish chain 3
INFO:cmdstanpy:finish chain 4
[4]:
| Mean | MCSE | StdDev | 5% | 50% | 95% | N_Eff | N_Eff/s | R_hat | |
|---|---|---|---|---|---|---|---|---|---|
| name | |||||||||
| lp__ | -83.0 | 0.0260 | 1.00 | -85.0 | -82.0 | -82.0 | 1500.0 | 22000.0 | 1.0 |
| mu | 4.6 | 0.0083 | 0.47 | 3.8 | 4.6 | 5.4 | 3300.0 | 46000.0 | 1.0 |
| sigma | 3.3 | 0.0063 | 0.34 | 2.8 | 3.3 | 3.9 | 2900.0 | 41000.0 | 1.0 |
[5]:
# check diagnostics
fit.diagnose();
INFO:cmdstanpy:Processing csv files: /var/folders/8d/cyg0_lx54mggm8v350vlx91r0000gn/T/tmpb0698seu/normal-202109031825-1-s6u3qyt6.csv, /var/folders/8d/cyg0_lx54mggm8v350vlx91r0000gn/T/tmpb0698seu/normal-202109031825-2-k1t3aeih.csv, /var/folders/8d/cyg0_lx54mggm8v350vlx91r0000gn/T/tmpb0698seu/normal-202109031825-3-z1ss6up9.csv, /var/folders/8d/cyg0_lx54mggm8v350vlx91r0000gn/T/tmpb0698seu/normal-202109031825-4-w_mnq3pl.csv
Checking sampler transitions treedepth.
Treedepth satisfactory for all transitions.
Checking sampler transitions for divergences.
No divergent transitions found.
Checking E-BFMI - sampler transitions HMC potential energy.
E-BFMI satisfactory.
Effective sample size satisfactory.
Split R-hat values satisfactory all parameters.
Processing complete, no problems detected.
[6]:
# access parameter chains
mu_chain = fit.stan_variable("mu")
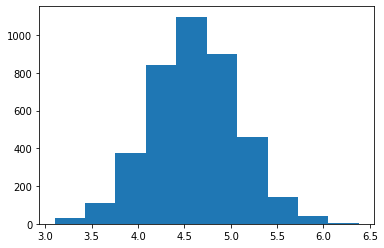
fig, ax = plt.subplots()
ax.hist(mu_chain)
print(np.mean(mu_chain))
print(np.shape(mu_chain)) # 1000 iterations x 4 chains
4.610008310000001
(4000,)
[7]:
# access all parameter chains in dict
fit.stan_variables()
[7]:
{'mu': array([4.57199, 4.16903, 4.58235, ..., 4.45103, 4.51904, 4.67652]),
'sigma': array([2.4773 , 3.92432, 2.74607, ..., 3.491 , 3.01159, 3.29009])}
[8]:
# access all chains and sample info
# e.g. lp__: log posterior value
# Don't worry too much about all the names with underscores__
fit.draws_pd()
[8]:
| lp__ | accept_stat__ | stepsize__ | treedepth__ | n_leapfrog__ | divergent__ | energy__ | mu | sigma | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | -85.8295 | 0.699286 | 0.725380 | 1.0 | 1.0 | 0.0 | 87.4636 | 4.57199 | 2.47730 |
| 1 | -83.7962 | 0.983581 | 0.725380 | 2.0 | 3.0 | 0.0 | 86.8479 | 4.16903 | 3.92432 |
| 2 | -83.1709 | 0.970982 | 0.725380 | 3.0 | 7.0 | 0.0 | 84.9906 | 4.58235 | 2.74607 |
| 3 | -83.1750 | 0.826682 | 0.725380 | 2.0 | 3.0 | 0.0 | 85.5702 | 4.16775 | 2.85137 |
| 4 | -82.3767 | 0.789408 | 0.725380 | 2.0 | 3.0 | 0.0 | 85.7000 | 4.61250 | 3.60720 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 3995 | -81.8448 | 0.968753 | 0.849615 | 2.0 | 3.0 | 0.0 | 82.2562 | 4.45911 | 3.20455 |
| 3996 | -82.5267 | 0.934572 | 0.849615 | 2.0 | 3.0 | 0.0 | 82.6128 | 4.71077 | 2.86769 |
| 3997 | -82.1453 | 0.766064 | 0.849615 | 2.0 | 3.0 | 0.0 | 84.9536 | 4.45103 | 3.49100 |
| 3998 | -82.0387 | 0.994238 | 0.849615 | 2.0 | 3.0 | 0.0 | 82.2948 | 4.51904 | 3.01159 |
| 3999 | -81.8205 | 0.917242 | 0.849615 | 2.0 | 3.0 | 0.0 | 82.8157 | 4.67652 | 3.29009 |
4000 rows × 9 columns
[9]:
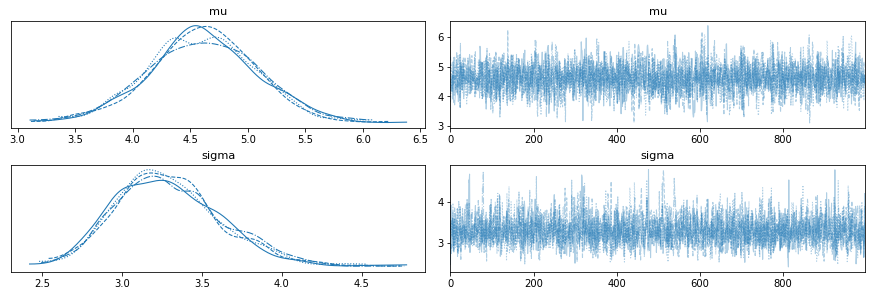
# use arviz to visualise the results if you like, it has common functionality built in
av.plot_trace(fit);
av.plot_pair(fit, marginals=True);
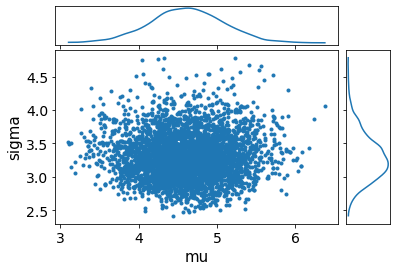
[10]:
# the av.plot.. calls return an axis that you can continue plotting on
ax = av.plot_pair(fit, var_names=["mu", "sigma"])
ax.axvline(mu, color="r")
ax.axhline(sigma, color="r")
[10]:
<matplotlib.lines.Line2D at 0x14346e760>
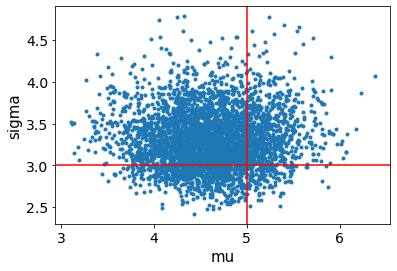
[11]:
# or you can pass them an axis
fig, ax = plt.subplots()
ax.scatter(mu, sigma, color="r")
av.plot_pair(fit, var_names=["mu", "sigma"], ax=ax)
[11]:
<AxesSubplot:xlabel='mu', ylabel='sigma'>
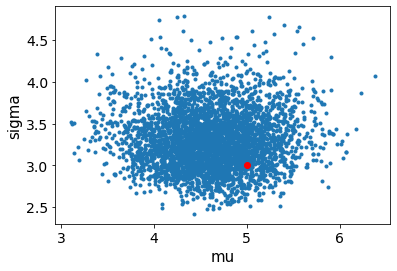
Ok, so it looks like everything is up and running. You can try changing the input data and see how the results change accordingly. Let’s investigate a few specific cases in the exercise below.
Exercise 1 (5 points):
What happens to the shape of the marginal distributions in the following cases:
Very little data (small
N)Large amounts of data (large
N)Narrow priors on
muandsigma
Make plots to summarise the comparison with the original case. What differences can be seen with what we might expect from a point estimate of these parameters using e.g. maximum likelihood.
[12]:
# to be completed...
Workflow overview
As we just saw above, building and fitting Bayesian model can be very easy with the tools available to us. However, for most scientific problems of interest, we won’t be dealing with idealised observations of normally-distributed data. The situation is to start out with data and a question. There is no simple recipe to go from this starting point to completing your analysis and drawing robust conclusions, but the idea of the workflow that we will discuss in this course is to present a general strategy for doing so.
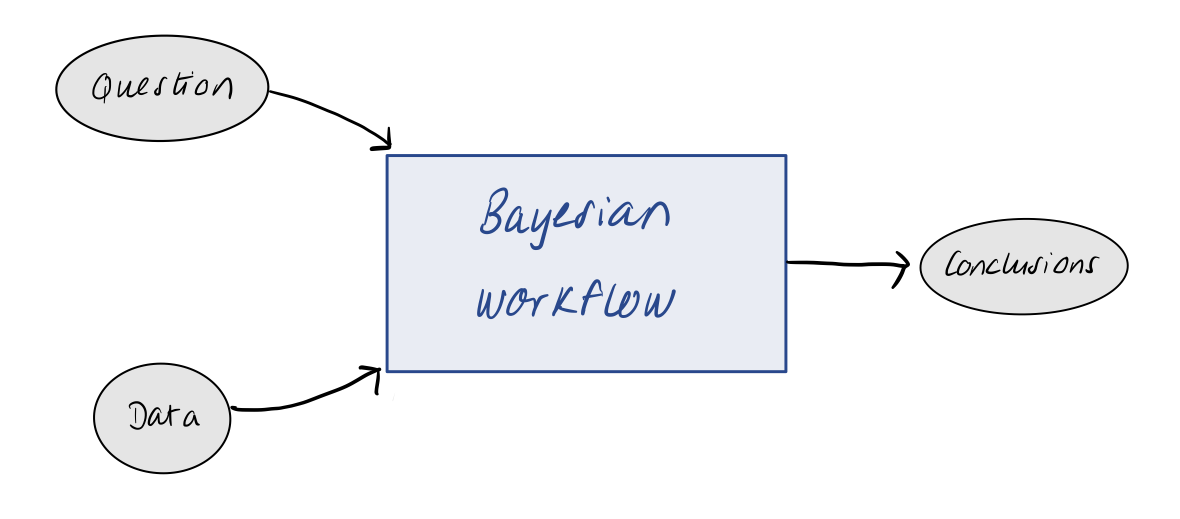
The workflow itself is made up of many different components and iterative processes. We want to start by using our question and data to define a meaningful statistical model. This stage often involves some form of exploratory data analysis and/or generative modelling. Once we have defined our model, we want to check if it makes sense or needs improvement. We therefore iterate through model development and implementation until we are satisfied. Our final model can be used to draw conclusions via inference. With the final model in hard, we can also think about performing model comparison with other models, or using the model to inform better experiment design in the future.
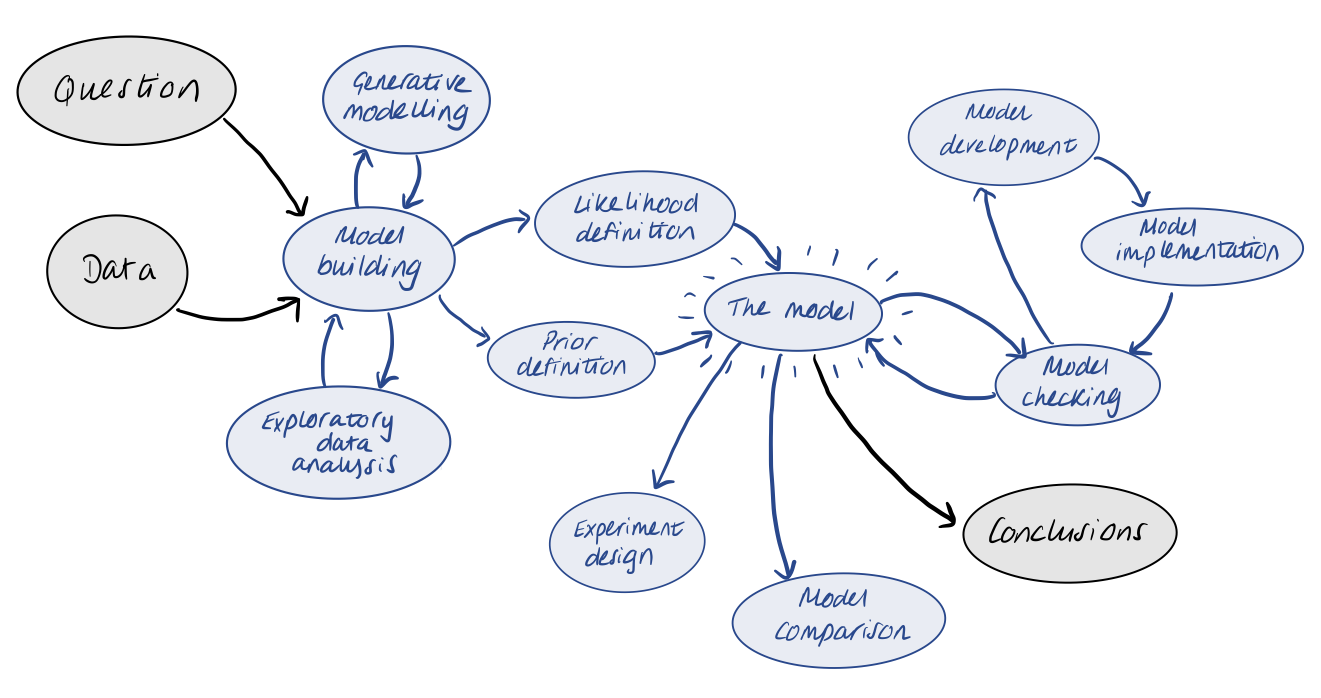
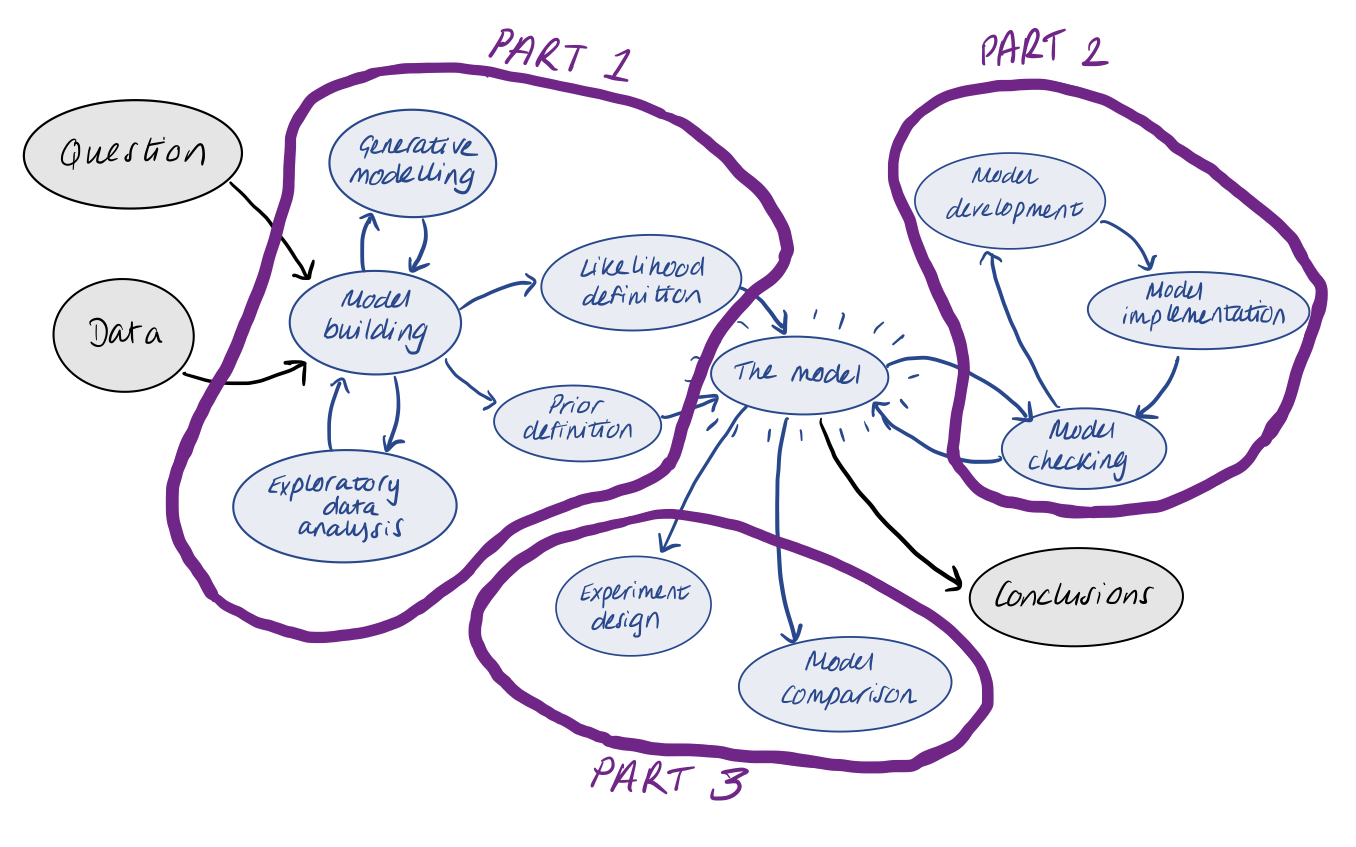
For this 3-day course, we will roughly break things up into the following categories…
A note on context
In this short course, we will not learn about frequentist statistical methods or machine learning approaches, which are both things you have probably heard of and may be interested in using in your research. While I might make fun of them a bit below, there are certainly cases where these could be more appropriate than what we will focus on.
So, before jumping into the Bayesian workflow, I’ll try to briefly highlight some similarities and differences between these topics, from the Bayesian perspective.
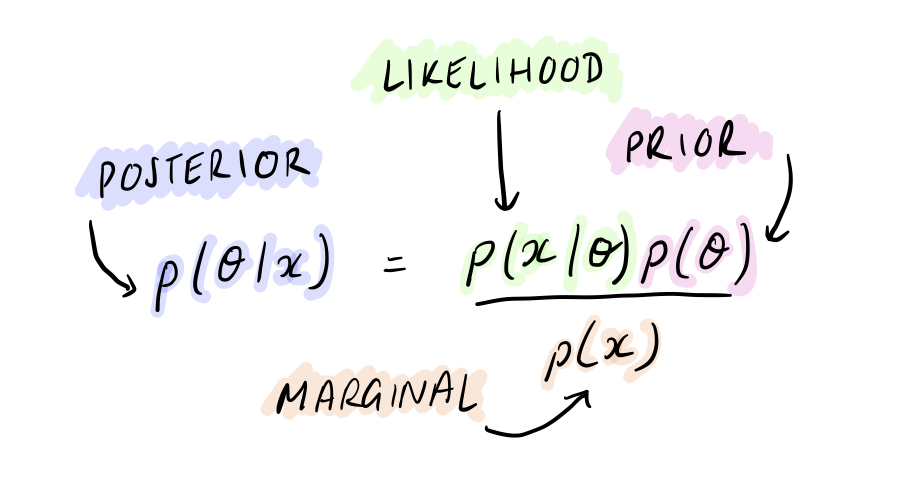
Let’s start by recalling Bayes’ theorem with data, \(x\), and model parameters \(\theta\):
Frequentist methods
We can start to think about some differences between Bayesian and frequentist statistical views by studying the following xkcd comic:

Both approaches involve a likelihood - \(p(\mathrm{answer}~|~\mathrm{sun~status})\). For this problem, the probability of the machine saying “yes” given the sun has not exploded is equal to the probablity of rolling two sixes, i.e.
One frequentist approach would be to perform a hypothesis test, with the null hypothesis being “sun ok” and the alternative hypothesis being “sun exploded”. The p-value is the probability that we observe a result as least as extreme as that observed, under the null hypothesis. In this case, that is equal to the first statement above. In many fields, it is standard to reject the null hypothesis if the p-value is < 0.05, leading us to conclude the sun has exploded…
Note: In physics it is common use a much stronger threshold for null hypothesis rejection such as “5 sigma”, or a p-value lower than 0.0000001, so we would not lose a bet with a Bayesian this time.
But on the Bayesian side, we would compute the posterior probability, \(p(\mathrm{sun~exploded}~|~\mathrm{yes})\), proportional on the prior probability, \(p(\mathrm{sun~exploded})\), which we would probably assume to be so tiny it would dominate our conclusion that the sun has not in fact exploded.
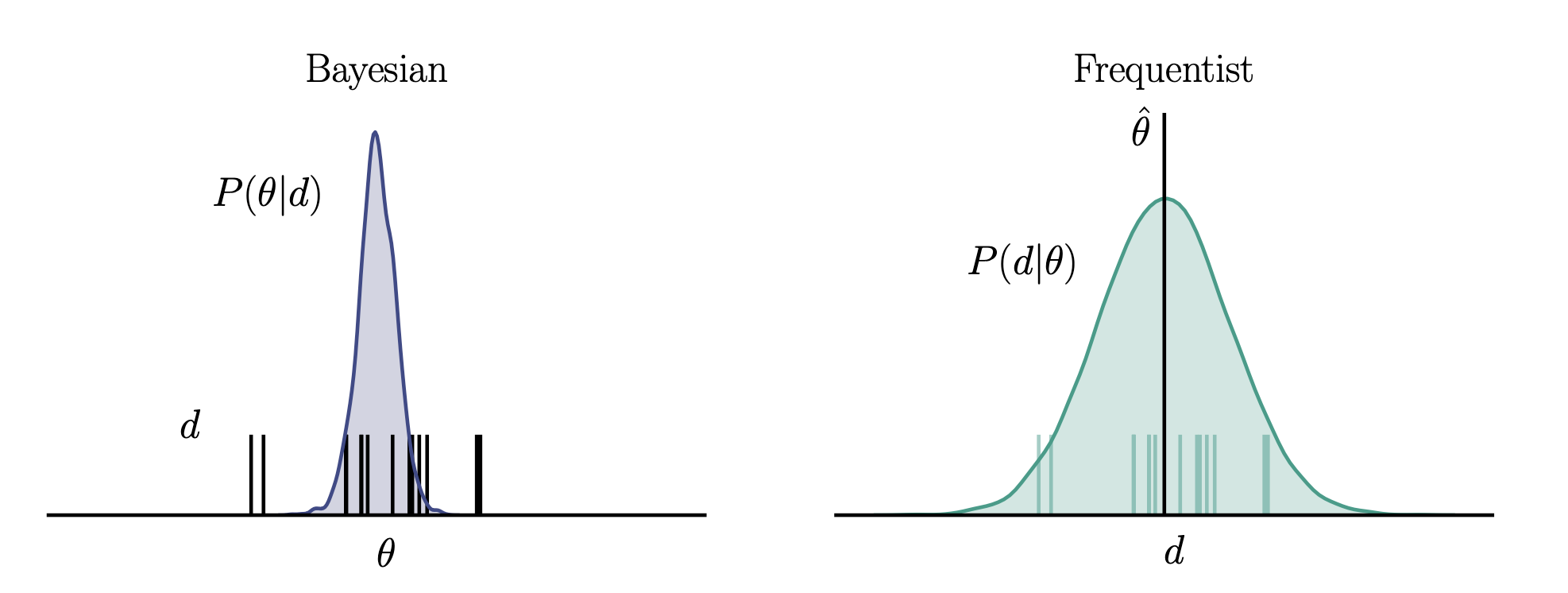
So is frequentist statistics just Bayesian statistics without priors? Unfortunately, it is not so simple. Sure, we can think about the cases where they might seem equivalent. In frequentist approaches it is typical to find the maximum likelihood estimate of a parameter based on data. Could this be the same as the maximum a posterior value of a parameter for a uniform prior?
However, it is important to keep in mind the different definitions of probability that the two views are based on: probability as a degree of belief vs. probability as a frequency in the limit of infinte observations. This also comes into the treatment of uncertainty. In the Bayesian view, the data are fixed and parameters are uncertain, whereas in the frequentist case, the true parameters are fixed, and we estimate them imperfectly due to uncertainty present in the data from finite sampling.
Machine learning
Machine learning is used to describe basically anything these days, but here I am referring to methods based on neural networks.

We can think about standard machine learning approaches as similar to maximum likelihood estimation. If we don’t know what the likelihood looks like, or cannot come up with a functional form for it, we can choose to represent it as a matrix of unknown weights.
We can then train a neural network with simulated or labelled data in order to learn the appropriate weights, an optimisation process that can be thought of as maximising the likelihood. Once trained, the resulting matrix of weights can be used like an operator to return the maximum likelihood estimate for new input data.
A key difference in this approach is that the likelihood itself is now a black box, and so it is not so clear how we should interpret our model or the resulting inferences. The quantification of uncertainty is also not straightforward. This is fine if you just want to make classifications or predictions, without asking why. That said, there is plenty of work being done on ways to interpret neural networks and methods exist to bring more Bayesian thinking in and allow uncertainty quantification.
Some more fun with Stan
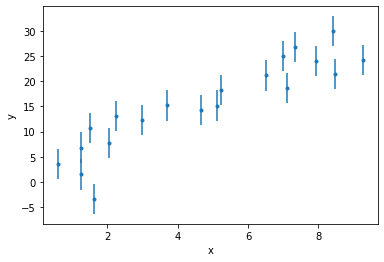
Let’s consider a simple linear regression problem. We observe a variable \(y\) that is related to a known quantity \(x\) via
where \(m\) and \(c\) are the unknown slope and intercept, to be determined. Our observation process introduces uncertainty, such that
where \(\sigma\) is a known quantity that is constant for all observations.
Exercise 2 (5 points): Write a Stan model for the above model, considering the dataset introduced below. Verify that it compiles.
[13]:
# load data
data = np.loadtxt("data/linear.dat")
x_obs = data[0]
y_obs = data[1]
sigma = data[2][0] # all the same
# plot
fig, ax = plt.subplots()
ax.errorbar(x_obs, y_obs, yerr=sigma, fmt=".")
ax.set_xlabel("x")
ax.set_ylabel("y")
[13]:
Text(0, 0.5, 'y')
[14]:
# to be completed...
# write stan code in a seperate .stan file
# compile
# stan_model = CmdStanModel(stan_file="...")
Exercise 3 (5 points): Build a dictionary to pass the data to Stan and fit the model. Visualise your results for \(m\) and \(c\).
[15]:
# to be completed...
Exercise 4 (5 points): We now learn that the \(x\) observations also have an associated uncertainty, \(\tau\), such that
We are told that \(\tau = 1\). Update your Stan model to include this information and repeat the fit to data. How does this affect our results for the line fit?
[16]:
# to be completed...
Homework exercise 1 (20 points): Find a coin and flip it 5 times, recording the answer as 0 for tails, and 1 for heads.
Write a Stan model for your observations.
Use it to determine the probability, \(p\), that a coin flip gives heads, given your observations.
Make another 5 observations of coin flips and add these to your original sample. How does this affect the result for \(p\)?
[17]:
#to be completed...